
El nuevo modelo, llamado VSSFlow, aprovecha una arquitectura creativa para generar sonido y voz con un único sistema unificado con resultados de última generación. Vea (y escuche) algunas demostraciones a continuación.
el problema
Actualmente, la mayoría de los modelos de vídeo a sonido (es decir, modelos entrenados para generar sonido a partir de vídeo silencioso) no son tan buenos para generar voz. De manera similar, la mayoría de los modelos de conversión de texto a voz no logran reproducir sonidos ajenos al habla, ya que están diseñados para un propósito diferente.
Además, los intentos anteriores de combinar ambas tareas a menudo se basan en la suposición de que el entrenamiento conjunto reduce el rendimiento, lo que lleva a configuraciones que enseñan el habla y el sonido en etapas separadas, lo que agrega complejidad al proceso.
Ante este escenario, tres investigadores de Apple, junto con seis investigadores de la Universidad Renmin de China, desarrollaron VSFlujoUn nuevo modelo de IA que puede generar efectos de sonido y voz a partir de vídeo silencioso en un solo sistema.
No solo eso, la arquitectura que crearon funciona de tal manera que el entrenamiento del habla mejora el entrenamiento del sonido y viceversa, sin interferir entre sí.
solución
En resumen, VSSFlow utiliza múltiples conceptos de IA generativa, incluida la conversión de transcripciones en secuencias de tokens de fonemas y el aprendizaje de reconstruir palabras a partir de palabras con coincidencia de flujo, que cubrimos aquí, esencialmente entrenando el modelo para comenzar de manera eficiente con palabras aleatorias y terminar con las señales deseadas.
Todo esto está integrado en una arquitectura de 10 capas que mezcla señales de video y transcripción directamente en el proceso de generación de audio, lo que permite que el modelo maneje tanto efectos de sonido como voz dentro de un solo sistema.
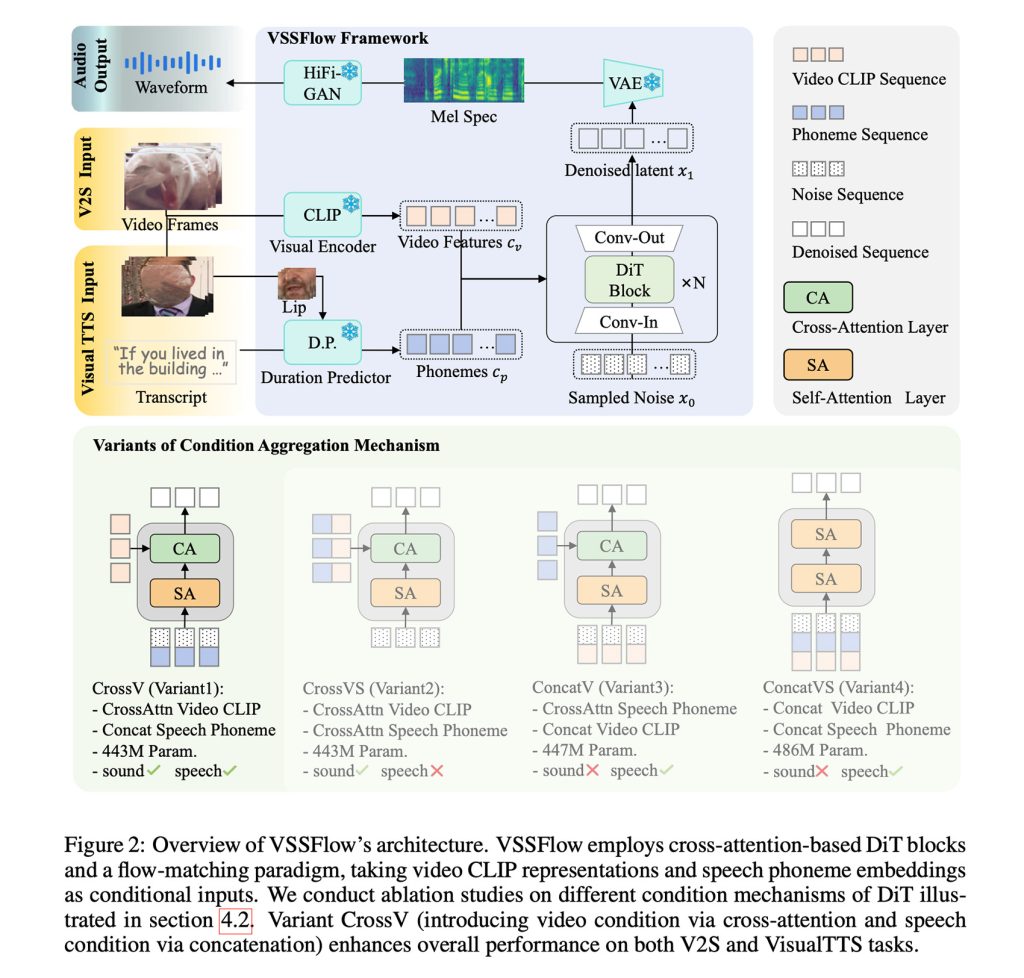
Quizás lo más interesante sea que los investigadores observaron que el entrenamiento conjunto sobre el habla y las palabras Ambos trabajan para mejorar el rendimiento.En lugar de competir entre los dos o reducir el desempeño general de ambas tareas.
Para entrenar VSSFlow, los investigadores alimentaron el modelo con una mezcla de videos de voz silenciosa con ruido ambiental (V2S), transcripciones (VisualTTS) y videos silenciosos combinados con datos de texto a voz (TTS), lo que le permitió aprender efectos de sonido y diálogo hablado simultáneamente en un único proceso de entrenamiento de un extremo a otro.
Es importante destacar que notaron que VSSFlow no podía generar automáticamente sonido de fondo y diálogo hablado al mismo tiempo en una sola salida.
Para lograr esto, ajustaron su modelo ya entrenado en un gran conjunto de ejemplos sintéticos donde el habla y los sonidos ambientales se mezclaban, de modo que el modelo aprendiera cómo deberían sonar ambos simultáneamente.
Usando VSSFlow
Para generar sonido y voz a partir de un vídeo mudo, el modelo comienza con ruido aleatorio y utiliza señales visuales muestreadas del vídeo a 10 fotogramas por segundo para dar forma a los sonidos ambientales. Al mismo tiempo, crear una transcripción de lo que se dice proporciona instrucciones precisas para la voz.
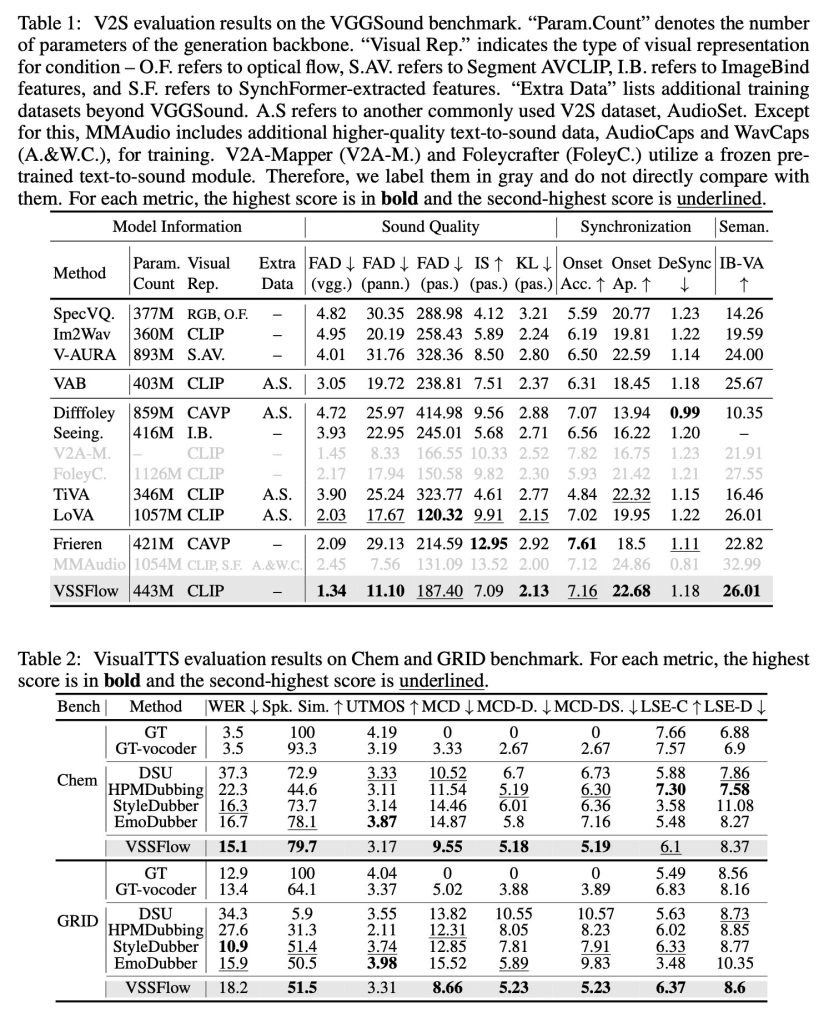
Cuando se prueba con modelos de tareas específicas creados solo para efectos de sonido o solo para voz, VSSFlow ofrece resultados competitivos en ambas tareas, liderando en varias métricas clave a pesar de utilizar un único sistema unificado.
Los investigadores publicaron varias demostraciones de resultados de ruido, voz y generación conjunta (a partir de un vídeo de Veo3), así como comparaciones entre VSSFlow y varios modelos alternativos. Puedes ver algunos resultados a continuación, pero asegúrate Página de demostración Véalos todos.
Y aquí hay algo realmente interesante: investigadores El código de VSSFlow es de código abierto en GitHubY el peso del modelo también está trabajando para abrirse. Además, están trabajando para proporcionar una demostración de estimación.
¿Qué podría pasar después, dicen los investigadores?
Este trabajo presenta un modelo de flujo unificado que integra tareas de vídeo a sonido (V2S) y de texto a voz visual (VisualTTS), estableciendo un nuevo paradigma para la generación de voz y sonido condicionado por vídeo. Nuestro marco demuestra un mecanismo eficiente de agregación de condiciones para incorporar condiciones de voz y video en la arquitectura DIT. Además, revelamos el efecto de impulso mutuo del aprendizaje conjunto palabra-habla a través del análisis, destacando el valor de un modelo generacional unificado. Para futuras investigaciones, hay varias direcciones que merecen una mayor exploración. En primer lugar, la falta de datos de vídeo, voz y sonido de alta calidad limita el desarrollo de modelos generativos unificados. Además, un importante desafío futuro es desarrollar mejores métodos de representación del sonido y el habla, que puedan preservar los detalles del habla manteniendo dimensiones compactas.
Para obtener más información sobre el estudio titulado “VSSFlow: Integración de la generación de voz y sonido condicionado por vídeo a través del aprendizaje conjunto”. Sigue este enlace.











{kind=link}